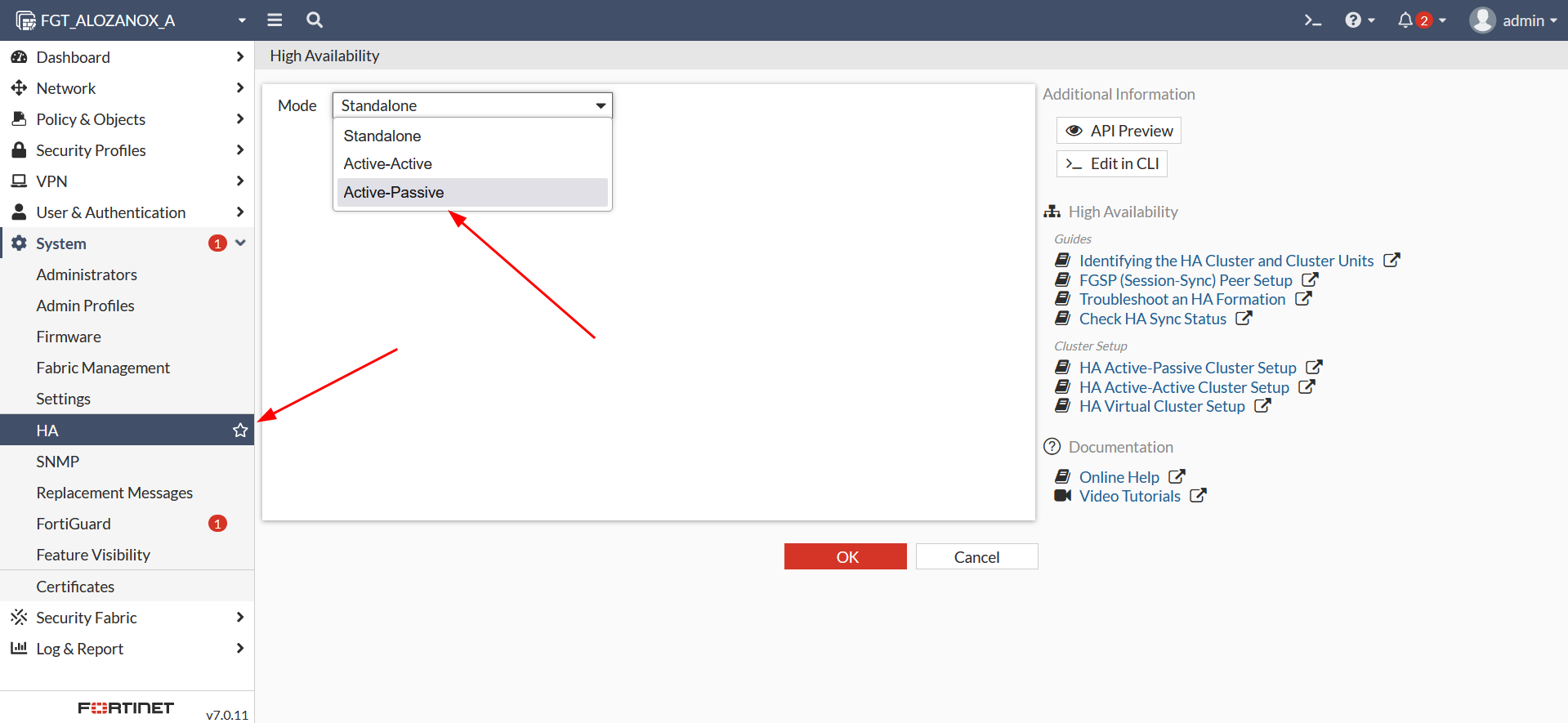
Para configurar un HA en FortiGate deberemos dirigirnos a la sección «System»>»HA». En este ejemplo configuraremos un HA activo-pasivo:
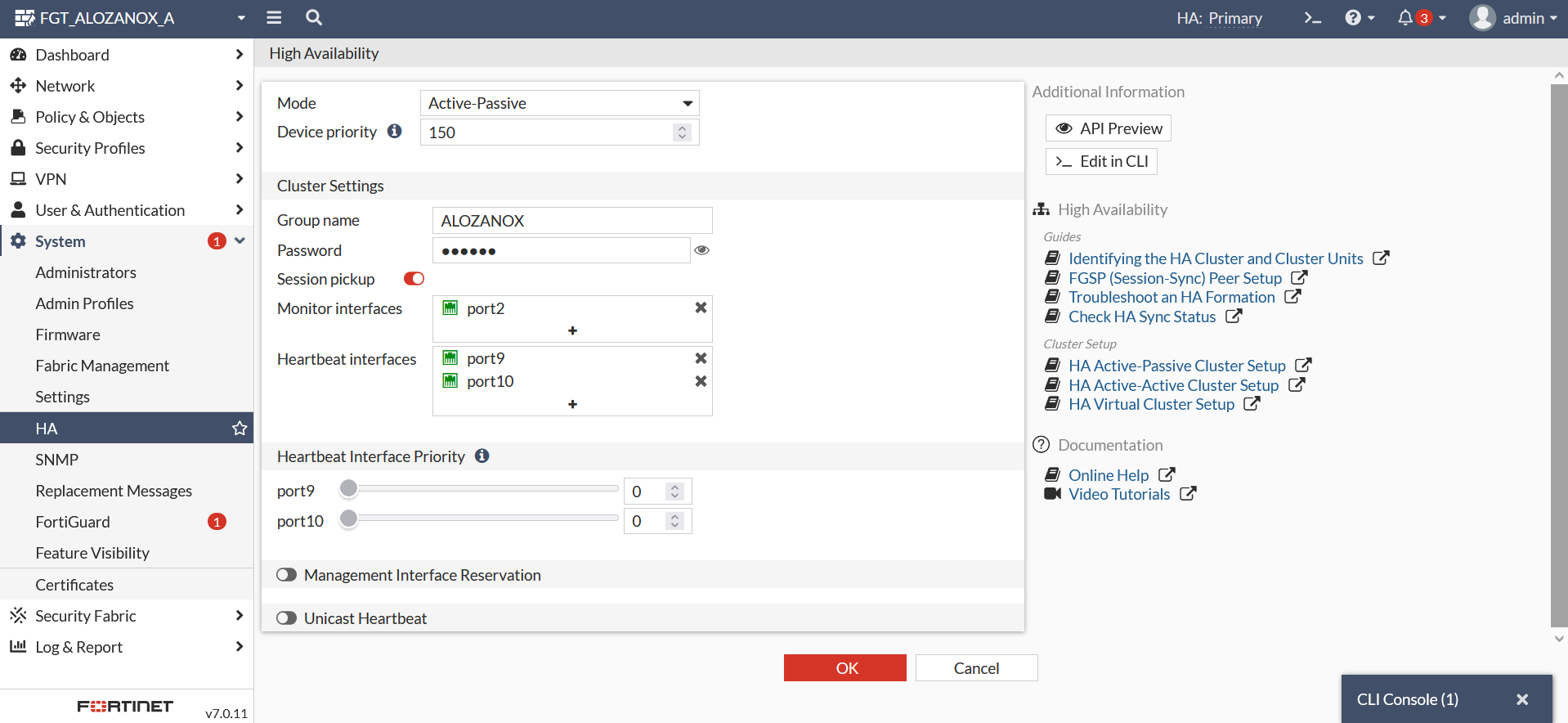
Indicamos un nombre para el grupo HA, la prioridad del nodo, los interfaces de Heartbeat y los interfaces que queramos monitorizar en caso de failover, es decir, en este caso monitorizaremos el port2, de tal manera que si en alguno de los nodos ese enlace se cae el otro nodo tomará el rol de primario automáticamente.
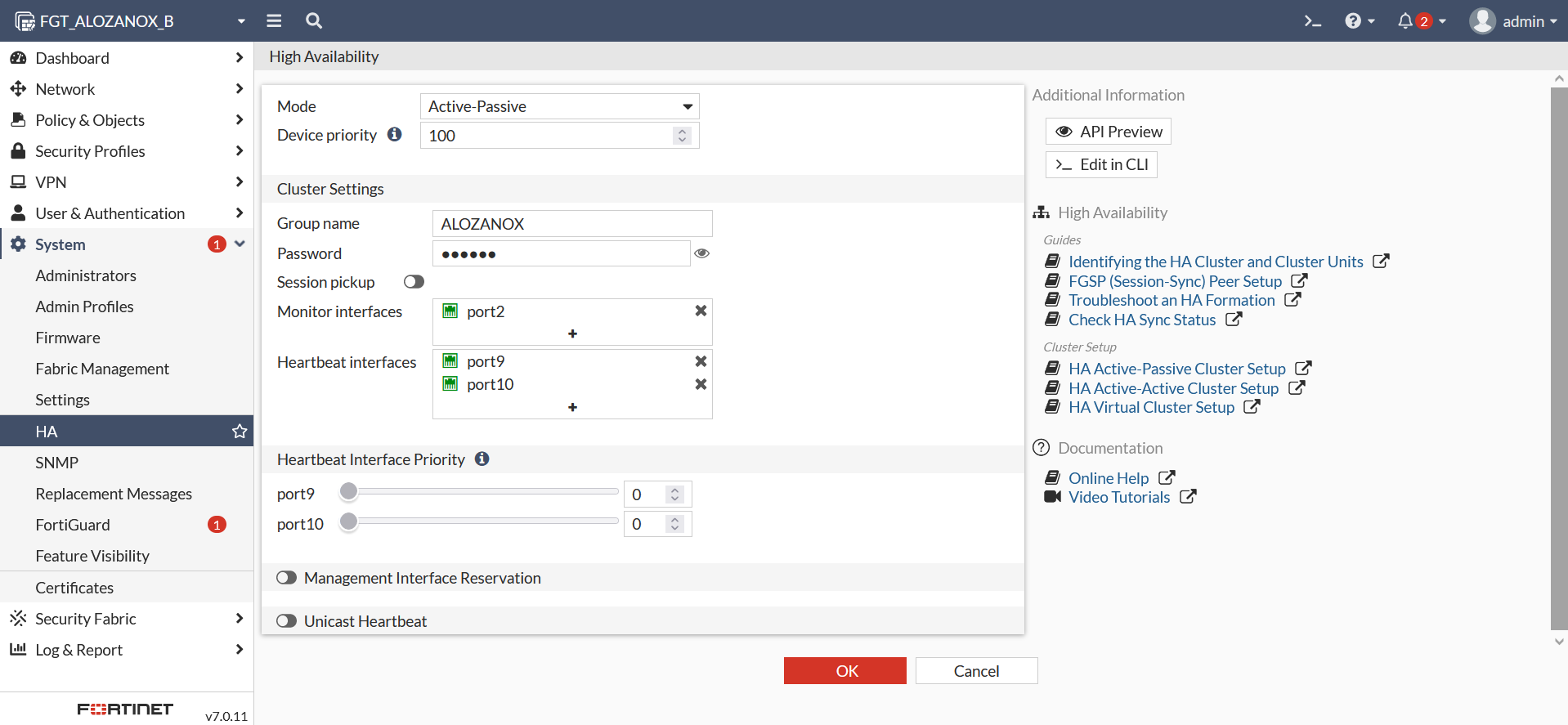
Una vez configurado el nodo-A pasamos a configurar el nodo-B:
Y ya estaría todo, en este momento ya está formado el HA entre los FortiGates, siendo el nodo-A el primario por tener mayor prioridad:

A continuación vamos a provocar un failover provocando una caída del puerto 2 en el nodo A ya que lo estamos monitorizando en el HA y observaremos cómo el nodo-B toma el rol de primario:
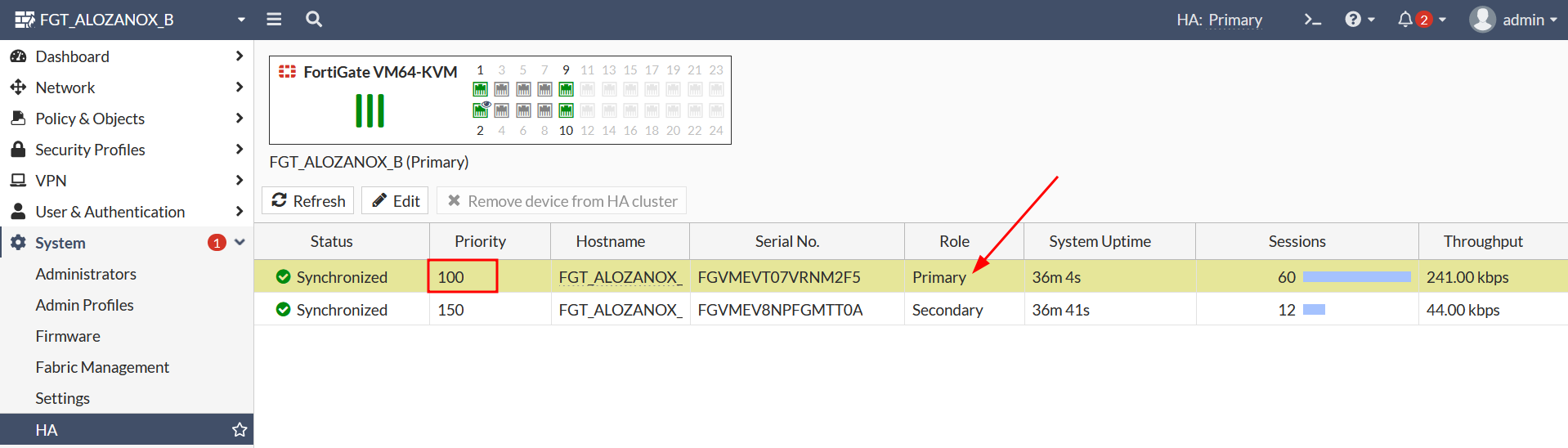
Como comentábamos, ahora el nodo-b es el primario aún teniendo una menor prioridad:
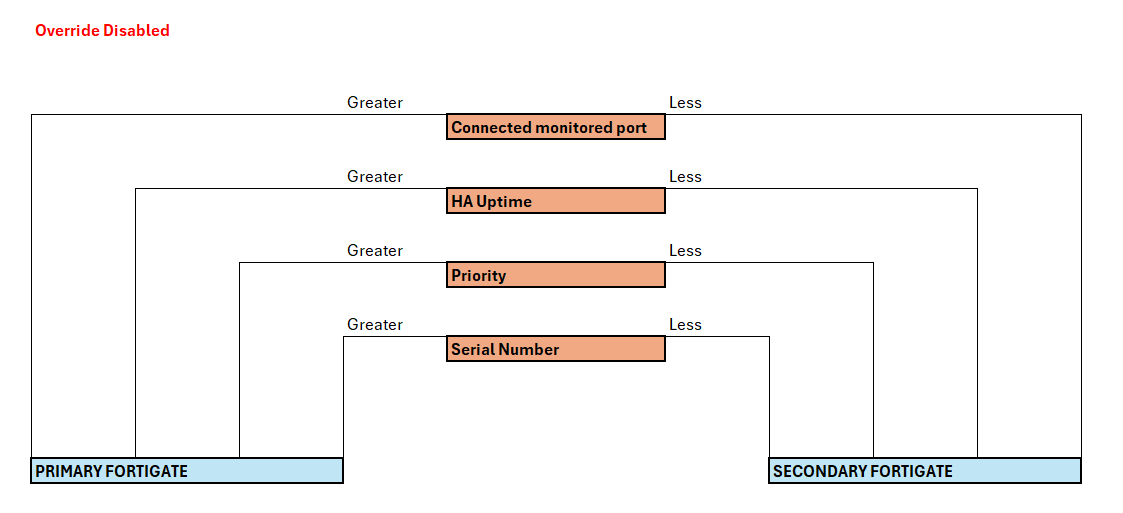
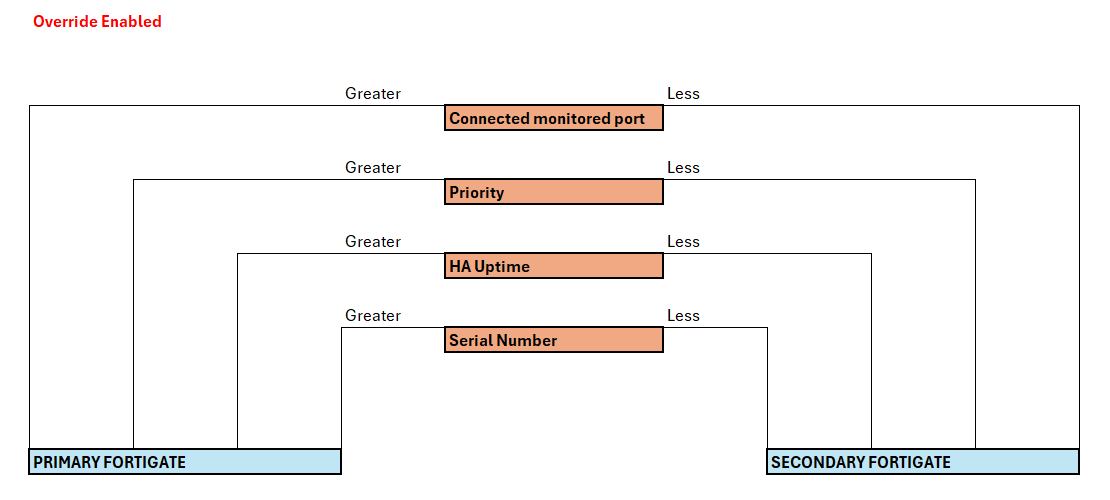
Para entender mejor este comportamiento nos vendrá bien repasar el siguiente esquema teniendo en cuenta si el parámetro override está habilidado o no, cambiará un poco el algoritmo de elección de primario respecto a la prioridad y el HA uptime:
Para comprobar el estado del HA por CLI podemos realizarlo del siguiente modo:
FGT_ALOZANOX_B # get system ha status
HA Health Status: OK
Model: FortiGate-VM64-KVM
Mode: HA A-P
Group: 0
Debug: 0
Cluster Uptime: 0 days 0:53:33
Cluster state change time: 2024-02-12 09:21:50
Primary selected using:
<2024/02/12 09:21:50> FGVMEVT07VRNM2F5 is selected as the primary because the value 0 of link-failure + pingsvr-failure is less than peer member FGVMEV8NPFGMTT0A.
<2024/02/12 09:00:00> FGVMEV8NPFGMTT0A is selected as the primary because its uptime is larger than peer member FGVMEVT07VRNM2F5.
ses_pickup: enable, ses_pickup_delay=disable
override: disable
Configuration Status:
FGVMEVT07VRNM2F5(updated 5 seconds ago): in-sync
FGVMEV8NPFGMTT0A(updated 1 seconds ago): in-sync
System Usage stats:
FGVMEVT07VRNM2F5(updated 5 seconds ago):
sessions=12, average-cpu-user/nice/system/idle=0%/0%/1%/98%, memory=42%
FGVMEV8NPFGMTT0A(updated 1 seconds ago):
sessions=4, average-cpu-user/nice/system/idle=0%/0%/0%/99%, memory=21%
HBDEV stats:
FGVMEVT07VRNM2F5(updated 5 seconds ago):
port9: physical/1000auto, up, rx-bytes/packets/dropped/errors=9294609/21080/0/0, tx=7493846/17686/0/0
port10: physical/1000auto, up, rx-bytes/packets/dropped/errors=7432193/16688/0/0, tx=5854220/13171/0/0
FGVMEV8NPFGMTT0A(updated 1 seconds ago):
port9: physical/1000auto, up, rx-bytes/packets/dropped/errors=7502781/17710/0/0, tx=9304076/21107/0/0
port10: physical/1000auto, up, rx-bytes/packets/dropped/errors=5861819/13188/0/0, tx=7441513/16709/0/0
MONDEV stats:
FGVMEVT07VRNM2F5(updated 5 seconds ago):
port2: physical/1000auto, up, rx-bytes/packets/dropped/errors=962/16/0/0, tx=300/5/0/0
FGVMEV8NPFGMTT0A(updated 1 seconds ago):
port2: physical/1000auto, up, rx-bytes/packets/dropped/errors=62/1/0/0, tx=960/16/0/0
Primary : FGT_ALOZANOX_B , FGVMEVT07VRNM2F5, HA cluster index = 0
Secondary : FGT_ALOZANOX_A , FGVMEV8NPFGMTT0A, HA cluster index = 1
number of vcluster: 1
vcluster 1: work 169.254.0.1
Primary: FGVMEVT07VRNM2F5, HA operating index = 0
Secondary: FGVMEV8NPFGMTT0A, HA operating index = 1Si queremos visualizar el histórico de los eventos del HA podemos lanzar el siguiente comando:
FGT_ALOZANOX_B # diagnose sys ha history read
version=1.1
HA state change time: 2024-02-12 09:21:50
message_count=4/512
<2024-02-12 09:21:50> FGVMEVT07VRNM2F5 is elected as the cluster primary of 2 member
<2024-02-12 09:00:00> new member 'FGVMEV8NPFGMTT0A' joins the cluster
<2024-02-12 09:00:00> FGVMEV8NPFGMTT0A is elected as the cluster primary of 2 member
<2024-02-12 08:59:59> hatalk startedUn método para provocar de nuevo el failover con el override disabled sería introducir el siguiente comando en el actual primario (Nodo-B):
FGT_ALOZANOX_B # diag sys ha reset-uptime De este modo, volverá el nodo-A a ser el primario aunque si os fijáis el uptime del equipo nodo-b sigue teniendo el mismo valor ya que el equipo no se ha reiniciado físicamente:
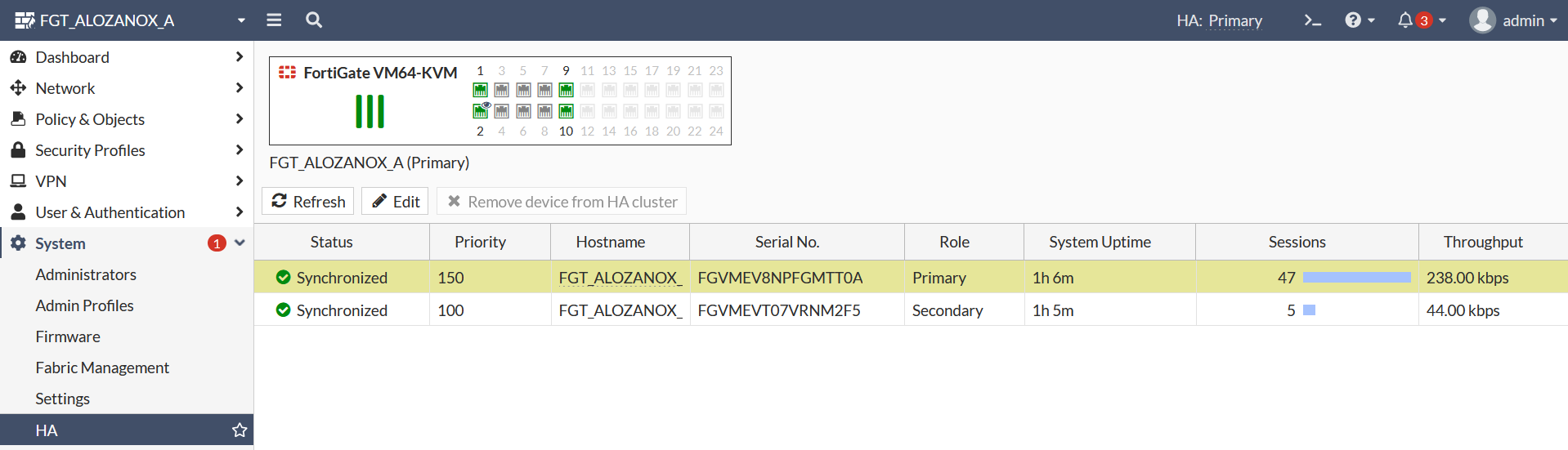
Para comprobar cuantas veces se ha utilizado el anterior comando deberemos realizarlo del siguiente modo:
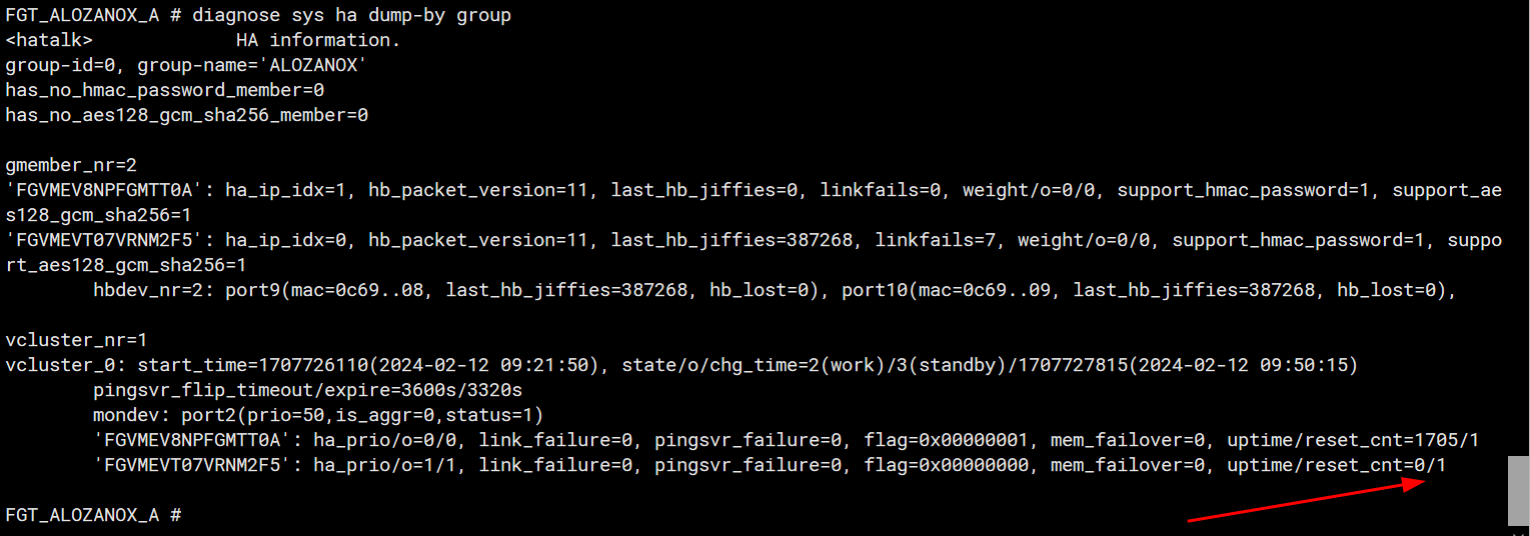
FGT_ALOZANOX_A # diagnose sys ha dump-by group