
Supongamos que tenemos un fichero donde se encuentran diferentes direcciones IP’s que se repiten y queremos saber cuantas veces se ha accedido/consultado dicha IP.
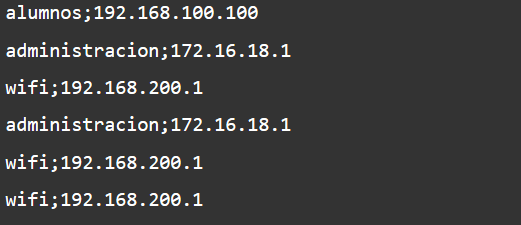
Mostramos las diez primeras líneas del fichero para comprobar el formato:
pi@platon:~ $ head fichero.csv
grupo;ip
alumnos;192.168.100.100
administracion;172.16.18.1
wifi;192.168.200.1
administracion;172.16.18.1
wifi;192.168.200.1
wifi;192.168.200.1
alumnos;192.168.100.100
alumnos;192.168.100.100
alumnos;192.168.100.100Introducimos el siguiente comando para contabilizar los datos:
cat fichero.csv | cut -f 2 -d ";" | sort | uniq -c | sort -nr | head -n5Este comando realizará las siguientes funciones:
- Abrir el fichero
- Cortar por la columna número dos «IP» que está delimitado por «;».
- Ordenar todos los registros.
- Obtener un único registro de cada valor y contabilizarlo.
- Ordenar de nuevo a la inversa y mostrar los cinco primeros registros

Esta combinación de comandos de Linux se puede extrapolar a cualquier otra situación donde queramos contabilizar los registros que se repiten en un fichero. Únicamente habría que ajustar los parámetros del comando «cut» al formato del fichero en cuestión.

